
Quale sarà l’impatto dell’ondata tecnologica di Intelligenza Artificiale (AI) e Machine Learning (ML), pilastri della Data Science, sull’industria del Wealth Management (WM)? Di certo l’ondata Fintech sta portando e porterà novità nella matura e relativamente poco digitale industria del WM. La parte forse più elettrizzante di questa rivoluzione tecnologica in atto riguarda AI e ML. Si tratta di strumenti incredibilmente potenti che risolvono già una discreta quantità di problemi della vita di tutti i giorni, oltre a imperversare (spesso in modo del tutto casuale e inappropriato) nei convegni Fintech, essendo ormai oggetto di discussioni da bar.
Per capire il possibile impatto di ML e AI sul vasto mondo del WM, mettiamo prima a fuoco l’argomento, facendo chiarezza sul significato di queste parole, spesso confuse tra loro e utilizzate a sproposito. Vediamo allora che cosa si cela dietro al gergo della Data Science.
Intelligenza Artificiale, Machine Learning e Data Science
C’è una bella distinzione tra ML e AI: il ML ha a che fare con l’inferenza, le previsioni, l’individuazione di pattern nascosti nei dati, il ragionamento automatico, la rappresentazione della conoscenza. Si tratta di generare e condensare informazioni che aiutano a prendere decisioni migliori. E fare previsioni. Ad esempio, sfruttare i Big Data per individuare nuovi cluster di clienti, nuovi bisogni ai quali associare prodotti, creando la giusta mappatura, analizzare e simulare il client conversion funnel… si può continuare per paginate e paginate, perché le applicazioni sono vastissime.
L’AI, intesa in senso stretto, è qualcosa di più del ML. L’AI è un computer che agisce come un Homo sapiens. Pertanto occorre che la macchina sappia interagire con gli umani utilizzando gli strumenti del Natural Language Processing, sfruttando al contempo gli algoritmi di Machine Learning . Le applicazioni tipiche sono i chatbot e gli assistenti virtuali.
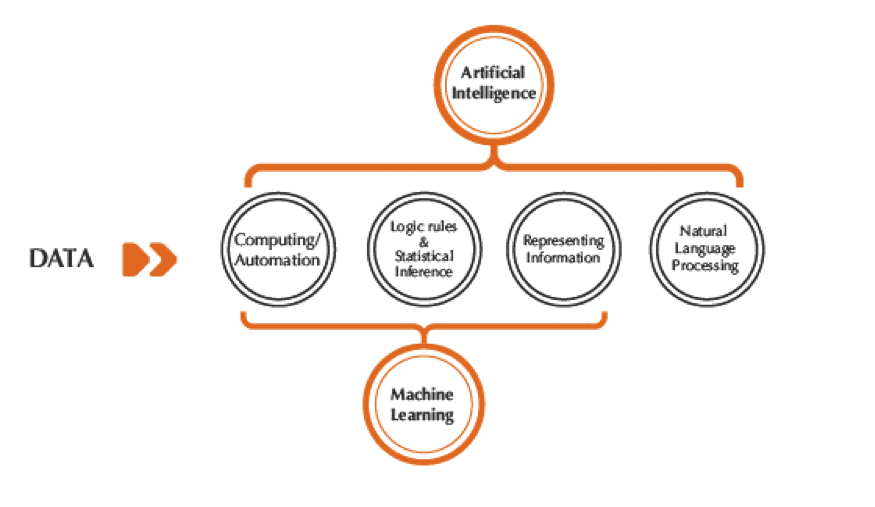
Figura 1 – Strettamente parlando l’Intelligenza Artificiale differisce dal Machine Learning per l’uso del Natural Language Processing (NPL) – vale a dire metodi di riconoscimento vocale, analisi testuale automatica, comprensione generazione di testi e discorsi –consentendo a un computer di agire come un umano.
Spesso l’idea di AI è però più ampia, e coincide con l’idea di Data Science, area multidisciplinare che si colloca all’interesezione di statistica, computer science, scienze sociali e Data Visualization (DataViz), senza dimenticare le conoscenze di dominio in termini di business (cioè la Business Intelligence). Al crescere dell’automazione nell’industria finanziaria si è iniziato a parlare di Financial Data Science: essenzialmente, e in modo non particolarmente sorprendente, applicazioni di Data Science alla finanza.
Nella pratica, tutte queste distinzioni pseudo-formali lasciano il tempo che trovano: la pratica consiste nell’utilizzare i dati a disposizione e tutti gli algoritmi e le tecniche di analisi note per estrarre valore dai dati. Occorono informazioni spendibili, che aiutano concretamente a generare più ricavi e/o ridurre costi. Il resto non conta.
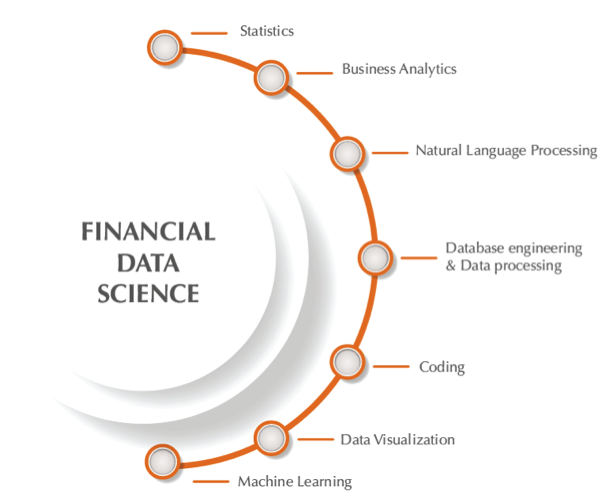
Figura 2 – Financial Data Science: un’area interdisciplinare che richiede different skills.
Financial Data Science: il vantaggio degli incumbent
Con l’affermarsi dei modelli di business “data –driven”, nell’industria della gestione dei risparmi grande è il timore degli “incumbent”, gli operatori tradizionali, nei confronti dei giganti della tecnologia: Amazon, Alphabet/Google, Facebook e Apple in testa. Comprensibile. Hanno masse enormi di utenti. E li conoscono alla perfezione, grazie alla loro capacità di analizzare i dati – la frontiera della Data Science non è certo nelle università (mi spiace), ma lì. Quando i Big Tech decideranno di entrare con forza sul mercato dei risparmi e degli investimenti, sarà battaglia. Gli intermediari finanziari tradizionali hanno però parecchie armi a loro disposizione.
Primo vantaggio: i dati
Praticamente ogni settore dell’economia ha accesso a una quantità di dati inimmaginabile anche solo una decina d’anni fa – e l’industria del WM non fa eccezione. Banche, assicurazioni, asset manager, hanno infatti un bel po’ di dati dai quali estrarre informazioni di enorme valore grazie alla Financial Data Science.
Tipicamente gli intermediari che si occupano di gestire gli investimenti sono in possesso dei seguenti tipi di dati:
- finanziari, relativi a posizioni e movimenti presenti e passati dei clienti e a flussi di pagamento – dati dai quali si possono ricavare, informazioni sulle dinamiche d’investiemnto, nonché sulle abitudini di consumo/risparmio;
- socio-demografici, come età, luogo di nascita e residenza, sesso, situazione familiare e via dicendo, fondamentali, ad esempio, per inquadrare l’investment life-cycle del cliente;
- le risposte al questionario Mifid (che, se ben disegnato e compliato correttamente, è una miniera d’informazioni), cruciale per estrarre il DNA finanziario del cliente;
- dati d’interazione cliente-intermediario, come quelli legati alla fruizione del sito, all’apertura di eventuali newsletter, uso di app, conversazioni telefoniche (rammento che devono essere conservate per cinque anni e se ne possono estrarre indici di attitudine e sentiment).
Anche senza dati ulteriori (legati ad esempio ai social media come Linkedin, Facebook, Twitter, o ad attività specifiche di “smart engagement”, come quiz, gaming, e via dicendo) è chiaro che si tratta di un patrimonio informativo notevole.
Innanzitutto sono informazioni ricchissime, perché specifiche: riguardano la sfera economico-patrimoniale. E poiché stiamo parlando di risparmi e investimenti, questo è evidentemente molto più rilevante delle passioni per teneri gattini o il meme del momento che si possono trovare su Instagram e Facebook.
Si tratta inoltre di un data-set che può essere “aumentato” – senza fare grandi voli di fantasia – incrociandolo con varie fonti dati esterne, in primis i dati dei mercati finanziari, quelli dell’economia e le news. Poi, volendo, vi sono svariati “alternative data sets”, ad esempio quelli legati a sentiment analysis, o geospaziali.
Vantaggio ancor più considerevole è che, in ottica GDPR, gli intermediari sono pienamente titolati a macinare questi dati in loro possesso (possesso pienamente autorizzato, cosa che forse non sarebbe sempre vera per i Big Tech), in quanto si tratta di dati inerenti la sfera finanziaria, utilizzati per risolvere problemi finanziari, quelli alla base del rapporto contrattuale.
Ma in che modo AI e ML possono concretamente aiutare l’industria del wealth management? Le applicazioni sono moltissime, e possono impattare l’intera “value chain”. Per esempio, con il supporto di dati e algoritmi, si possono affrontare e risolvere problemi come::
- individuare e comprendere i bisogni finanziari dei clienti e i loro obiettivi reali;
- costruire modelli predittivi del comportamento dei clienti (ad esempio se acquisterà o meno un dato prodotto finanziario/assicurativo);
- individuare i clienti attualmente piccoli ma con elevato potenziale di crescita;
- migliorare la segmentazione dei clienti, offrendo loro soluzioni d’investimento e servizi accessori personalizzati, migliorando la user experience a costi molto bassi;
- individuare quali bisogni finanziari sono soddisfatti da un dato prodotto, e per quali obiettivi è consigliabile;
- supportare le reti di consulenti finanziari, agenti e altri relationship manager con informazioni mirate sui clienti e recommendation systems relativi alle migliori soluzioni da offrire ai clienti, in base ai loro specifici bisogni e caratteristiche;
- gestire la compliance in tempo reale;
- simulare l’impatto di eventi di mercato su processi, masse in gestione, costi e margini – attuando qualle che è probabilmente la più utile forma di risk management per un wealth manager (molto più che calcolare il VaR al 99% a una settimana sui portafogli dei clienti);
- catturare e analizzare nuove fonti di dati.
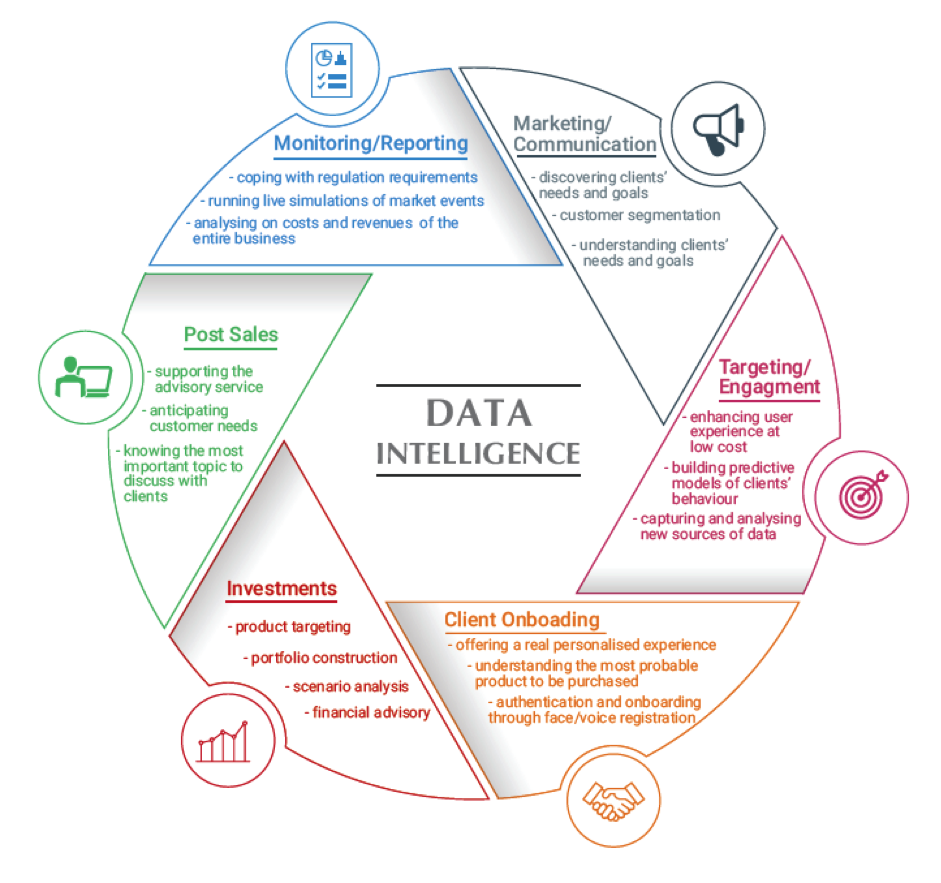
Figura 3 – I dati dovrebbero essere al cuore del processo di wealth management, supportando e indirizzando tute le principali azioni.
Quindi le aziende finanziarie possono estrarre valore tangibile da numerose fonti dati interne ed esterne utilizzando gli strumenti della Data Science. Tuttavia, la quantità di dati non è l’aspetto più rilevante.
Secondo vantaggio: conoscenza di dominio
I dati sono la materia prima, certo. E la loro quantità rileva, ma la qualità rileva di gran lunga di più. La rilevanza dei dati in termini di business è strategica: nei problemi di ML legati alla gestione dei risparmi, gettare nel bidone degli algoritmi supervisionati o non-supervisionati i dati in modo indiscriminato raramente è una buona idea. Il settore finanziario è infatti fortemente regolamentato, con prassi professionali dalla logica forte e ben consolidata: sarebbe follia non includere queste informazioni “di struttura” nel processo di number crunching. La “features selection”, cioè la selezione delle variabili di input è cruciale se non si vogliono avere algoritmi che funzionano bene in fase di training ma sono incomprensibili e funzionano male nell’opertività quotidiana.
La comprensione del business che sta dietro e intorno ai dati è di gran lunga più importante della soluzione tecnica, cioè di sviluppo di modelli complessi ma fini a sé stessi, e deve essere tenuta in conto nello sviluppo dei modelli stessi. Modelli black-box molto grandi, nella nostra esperienza (Virtual B SpA in larga parte di questo si occupa) tendono all’overfitting e al data snooping: termini che, in sostanza, significano che il modello non ha penetrato davvero la logica del problema che vuole risolvere, bensì ha operato una sofisticatissima interpolazione con scarso valore predittivo. Più dati ci sono, più complesso è il modello, meno conoscenza di dominio si ha, e più è probabile, insidioso e difficile da riconoscere l’overfitting.
Inoltre, per molte applicazioni algoritmiche legate alla gestione dei risparmi i regulators vogliono poter effettuare il “look through”, cioè aprire la scatola del modello per capirne le logiche e i nessi causali. Ragionevole. In questi casi, aver attuato un’analisi via deep learning, per esempio, scaraventando dentro la black box tutte le informazioni possibile, non è esattamente una grande idea.
Ecco perché la conoscenza di dominio è fondamentale, se si vuole utilizzare la Data Science per azioni concrete, misurabili, con un elevato ROI sugli investimenti in tecnologia. Questo è un enorme vantaggio degli intermediari finanziari. Questo è il primo articolo di una serie: nei prossimi vedremo alcune applicazioni concrete.
Take home
Gli intermediari finanziari sono già oggi in possesso di basi dati di grande valore. Si tratta di sfruttarle con intelligenza e senso pratico, mettendo al lavoro gli strumenti offerti dalla Financial Data Science, cioè algoritmi di Machine Learning e tutto ciò che viene in senso lato connotato come Intelligenza Artificiale.
La Financial Data Science, in breve, fa esplodere efficienza e scalabilità. Che si traducono in maggiore produttività. Cioè margini migliori. Di questi tempi, non è male.

