
C’è aria di novità nel mondo degli investimenti passivi, nell’ultimo decennio enormemente cresciuti in termini di popolarità e di masse in gestione: parliamo del direct indexing.
Fino a oggi parlare di investimento passivi ha per lo più coinciso con parlare di ETF, o altri prodotti analoghi, in generale denominati ETP. Il successo commerciale degli ETF deriva dal fatto che si tratta di strumenti semplici nella forma e nelle modalità di scambio, economici in termini commissionali capaci di offrire diversificazione dei rischi finanziari e – molto spesso – con performance migliori di quelle dei fondi attivi. L’offerta di ETF sul mercato è inoltre vastissima, e copre larga parte delle asset class azionarie e obbligazionarie, aree geografiche, settori, tipologie e stili d’investimento.
Tuttavia, grazie a un insieme di nuove tecnologie a disposizione degli operatori e alla collaborazione tra aziende Fintech e colossi bancari, si è ora affacciato sul mercato il direct indexing, da molti considerato l’evoluzione naturale degli ETF. Svariati grandi attori del mondo finanziario, tra i quali Vanguard, BlackRock, Morgan Stanley, Fidelity, hanno infatti recentemente effettuato acquisizioni di aziende Fintech dotate della tecnologia necessaria ad attuare il direct indexing, e hanno piani di sviluppo piuttosto grandiosi in merito, a quanto si sa.
Ma, esattamente, che cos’è il direct indexing? E perché c’è questo fermento?
Direct indexing 101
Il direct indexing è il processo di replica diretta di indici da parte dell’investitore finale. Quindi, attraverso le piattaforme di direct indexing, il cliente del servizio acquista direttamente i titoli necessari a replicare l’indice o gli indici che ha prescelto.
In pratica, chi utilizza il direct indexing, anziché trovarsi sul proprio conto uno o più ETF, oppure fondi comuni, si trova in possesso di decine, o centinaia, di titoli che costituiscono la replica dell’indice.
Una volta scelto l’indice o gli indici da replicare, i tipici passi fondamentali di un processo di direct indexing sono quindi i seguenti, reiterati nel tempo:
- ottenere la composizione dell’indice, cioè identificativi univoci e peso dei titoli che costituiscono l’indice;
- definire il portafoglio di replica, cioè la lista dei titoli e le quantità associate;
- acquistare i titoli che costituiscono il portafoglio di replica;
- ribilanciare il portafoglio affinché continui a riflettere la composizione dell’indice quando questo varia.
Se si analizzano più da vicino questi passaggi, si comprende come sia un processo per nulla nuovo, ma non banale, e come tragga beneficio dall’evoluzione tecnologica di questi anni.
Partiamo dalla composizione. Gli index provider generalmente forniscono la composizione dietro pagamento di una commissione, a volte cospicua. In realtà, utilizzando processi di clonazione statistica dell’indice a partire dalla sola serie storica dei suoi valori (o dei rendimenti), impiegando modelli dinamici a variabili latenti, si può anche fare a meno della composizione, con risultati apprezzabili. Parlare di clonazione ci porta però dritti al cuore del problema di index tracking. Apparentemente è un problema banale agli occhi dei non addetti ai lavori: basta acquistare nelle opportune quantità tutti i titoli che compongono l’indice. Tuttavia, per far ciò, occorrono generaslmente capitali enormi, e per la maggior parte degli investitori non è nemmeno così desiderabile, visto che ci si troverebbe con una moltitudine di piccolissime posizioni in titoli, magari illiquidi. È dunque molto più comune replicare la performance di un indice con un portafoglio, il cosiddetto “tracking portfolio”, costituito da un numero contenuto di titoli. In tal caso si parla di “portafoglio sparso”, che mima il comportamento di un indice possedendo però solo un sottoinsieme astutamente selezionato dei titoli che lo costituiscono. Questo consente la replica anche con piccoli capitali (ciò dipende comunque dall’indice specifico, è difficile generalizzare).
Ora, per mimare con appena qualche decina di titoli ben selezionati la dinamica di indici costituiti da centinaia o addirittura migliaia di titoli (alcuni con una quotazione in assoluto elevata – si pensi a Alphabet, il cui prezzo si aggira oggi sui 3000 dollari) servono algoritmi. Ne esistono molti, perché l’index tracking non è certo una novità. Senz’altro l’attuale diffusione del Machine Learning – nonché di librerie e piattaforme tecnologiche che lo rendono operativo con grande efficienza – è d’enorme aiuto.
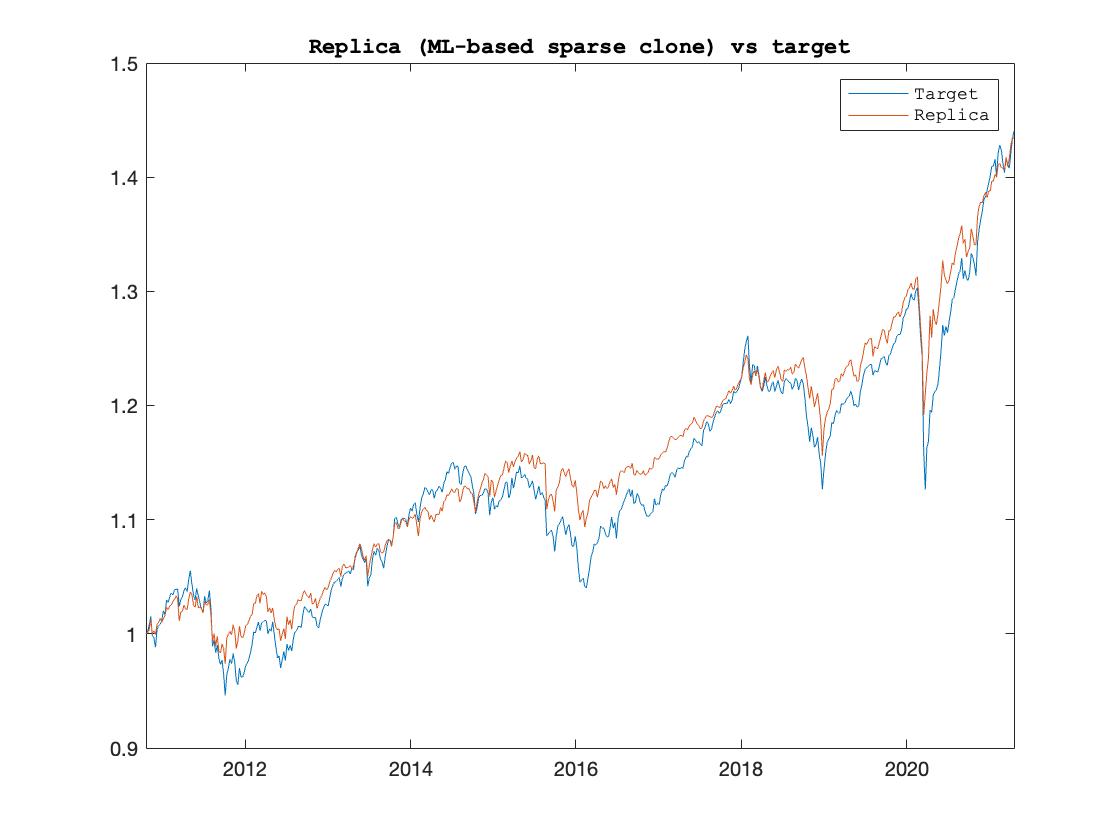
La lista di algoritmi utilizzabili è dunque lunga. Si va da semplici algoritmi basati sul campionamento stratificato (ad esempio per area geografica/settore) dell’universo di titoli che costituiscono l’indice, ad altri che utilizzano tecniche tipiche dell’Operational Research, ad esempio Mixed-Integer Programming (MIP), euristiche come gli algoritmi genetici, a metodi più tipici del Machine Learning come Non-Negative Lasso Regression, nonché combinazioni di queste tecniche. Alcuni di questi algoritmi possono arrivare a replicare indici senza conoscerne la composizione, semplicemente analizzandone la performance storica. Il che può essere un bel vantaggio, specie per indici target enormi, illiquidi, poco trasparenti, come gran parte degli indici legati agli investimenti alternativi. Si veda la Figura 1 per un esempio pratico di replica (out-of-sample) di un indice che combina un vasto indice di Hedge Fund ad altri indici tradizionali con migliaia di titoli all’interno.
Periodicamente, bisognerà inoltre effettuare acquisti e vendite di titoli per ribilanciare la composizione del portafoglio, in modo che continui a riflettere quella dell’indice target, che ovviamente cambia nel tempo (con frequenza e modalità differenti a seconda dell’indice). Un problema centrale nel processo di index tracking è pertanto contenere i costi di transazione, che includono sia commissioni dirette e costi di “slippage”, evitando transazioni superflue.
Visto il livello di quotazione di alcuni titoli (Amazon si aggira sui 3500 dollari…), per effettuare il direct indexing servono piattaforme di esecuzione degli investimenti in grado di operare in modo fluido su vaste quantità di clienti e di titoli, acquistando anche solo piccole frazioni di essi, cosa possibile oggi, ma impensabile su questa scala una decina di anni fa.
Insomma, il direct indexing forse sembra banale ma non lo è. È reso possibile dall’innovazione tecnologica, dalla democratizzazione finanziaria e sarebbe stato inconcepibile qualche anno fa, quando intermediari come Robinhood non esistevano e processi di questa complessità erano appannaggio esclusivo di grandi investitori istituzionali.
Accesso e costi
Di certo la dimensione patrimoniale non è la discriminante principale. Le soglie di accesso al direct indexing si sono infatti abbassate drasticamente negli USA, dove questo servizio comincia davvero a prendere piede: oggi basta mettere sul piatto qualche decina di migliaia di dollari. E il trend di riduzione della soglia d’accesso continua. In Italia vi sono aziende che puntano nel breve ad offrire il direct indexing per somme inferiori a diecimila euro.
Parlando di costi, negli USA, l’incidenza dei costi (circa 0,20% all’anno in media) è grosso modo allineata agli ETF. In Europa, e soprattutto in Italia, il fenomeno è ancora una novità assoluta, ma si parla comunque di costi bassi.
Perchè attuare il direct indexing?
Assodato che il direct indexing è una forma di democratizzazione finanziaria che consente al privato cittadino di emulare una multinazionale finanziaria che gestisce ETF, resta però da domandarsi quale tipo di risparmiatore ne abbia davvero bisogno, visto che si porta dietro una certa complessità. La domanda è più che ragionevole, vista l’esistenza di migliaia di ETF che consentono di investire in qualsiasi cosa, ovunque, semplicemente, e per giunta a costi bassi, mentre il direct indexing, seppur effettuato attraverso piattaforme specializzate comporta un aumento della complessità.
Ebbene, le ragioni principali per complicare in questo modo un portafoglio di investimenti sono due: le tasse e la personalizzazione.
Partiamo dalle tasse: possedere direttamente i titoli permette di diminuire gli oneri fiscali, visto che le perdite su alcuni titoli compensano i guadagni su altri, de facto riducendo l’imponibile. È possibile dunque effettuare un’ottimizzazione fiscale, attuando strategie di “tax-loss harvesting”, che in sostanza prevedono di vendere titoli in perdita per ridurre le tasse sulle plusvalenze.
Poi c’è la questione della personalizzazione. Con il direct indexing si può sostanzialmente replicare accuratamente un indice scartando alcuni titoli indesiderati per svariate ragioni. Ad esempio per questioni di sostenibilità. Vista la crescente sensibilità degli investitori verso temi ESG, la possibilità di replicare la dinamica di una Borsa escludendo però dal proprio portafoglio aziende considerate indesiderabili è un beneficio non da poco. Comunque, al di là del tema ESG, la casistica può evidentemente essere assai varia.
In conclusione, il direct indexing è una novità ad alto contenuto di tecnologia finanziaria che probabilmente si rivolge a una clientela sofisticata, costituita da investitori esperti, attenti ad aspetti fiscali e all’iper-personalizzazione. Per molti altri investitori, un portafoglio ben costruito e ben diversificato di ETF o fondi continuerà verosimilmente a funzionare a meraviglia.
Raffaele Zenti
Co-Founder, Chief Data Scientist – Virtual B SpA

