Viene pubblicata oggi la nuova Nota di stabilità finanziaria e vigilanza “Il rischio climatico per le banche italiane: un aggiornamento sulla base di un’indagine campionaria”…
Lug
01
2022
Viene pubblicata oggi la nuova Nota di stabilità finanziaria e vigilanza “Il rischio climatico per le banche italiane: un aggiornamento sulla base di un’indagine campionaria”…
The European Securities and Markets Authority (ESMA), the EU’s securities markets regulator, has announced its recognition of two central counterparties (CCPs) established in the United States…
https://www.esma.europa.eu/press-news/esma-news/esma-updates-applications-recognition-us-based-ccps

L’iniziativa di Finriskalert.it “Il termometro dei mercati finanziari” vuole presentare un indicatore settimanale sul grado di turbolenza/tensione dei mercati finanziari, con particolare attenzione all’Italia.
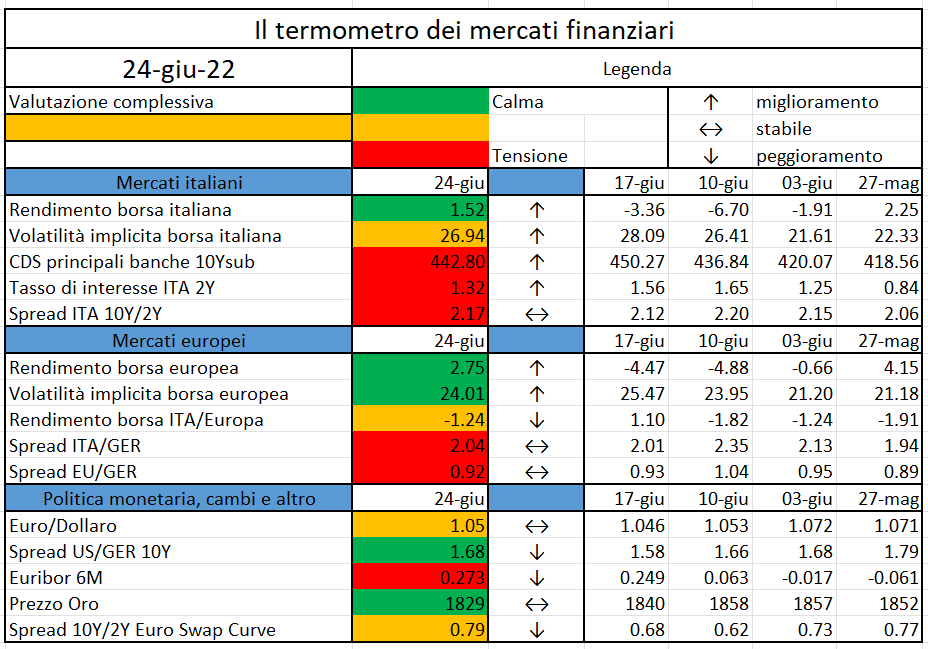
Significato degli indicatori
I colori sono assegnati in un’ottica VaR: se il valore riportato è superiore (inferiore) al quantile al 15%, il colore utilizzato è l’arancione. Se il valore riportato è superiore (inferiore) al quantile al 5% il colore utilizzato è il rosso. La banda (verso l’alto o verso il basso) viene selezionata, a seconda dell’indicatore, nella direzione dell’instabilità del mercato. I quantili vengono ricostruiti prendendo la serie storica di un anno di osservazioni: ad esempio, un valore in una casella rossa significa che appartiene al 5% dei valori meno positivi riscontrati nell’ultimo anno. Per le prime tre voci della sezione “Politica Monetaria”, le bande per definire il colore sono simmetriche (valori in positivo e in negativo). I dati riportati provengono dal database Thomson Reuters. Infine, la tendenza mostra la dinamica in atto e viene rappresentata dalle frecce: ↑,↓, ↔ indicano rispettivamente miglioramento, peggioramento, stabilità rispetto alla rilevazione precedente.
Disclaimer: Le informazioni contenute in questa pagina sono esclusivamente a scopo informativo e per uso personale. Le informazioni possono essere modificate da finriskalert.it in qualsiasi momento e senza preavviso. Finriskalert.it non può fornire alcuna garanzia in merito all’affidabilità, completezza, esattezza ed attualità dei dati riportati e, pertanto, non assume alcuna responsabilità per qualsiasi danno legato all’uso, proprio o improprio delle informazioni contenute in questa pagina. I contenuti presenti in questa pagina non devono in alcun modo essere intesi come consigli finanziari, economici, giuridici, fiscali o di altra natura e nessuna decisione d’investimento o qualsiasi altra decisione deve essere presa unicamente sulla base di questi dati.

L’azienda di DeFi ha congelato i depositi per mancanza di liquidità, miliardi in fumo e Bitcoin ai minimi dal 2020. Ametrano (CheckSig): “Spesso è difficile distinguere la vera innovazione tecnologica da progetti velleitari e poco affidabili”. [Continua su HuffPost.it]
Bitcoin plunged through several closely watched price levels to the lowest since late 2020 as evidence of deepening stress within the crypto industry keeps piling up against a backdrop of monetary tightening.
L’intervento della Bce raffredda lo spread, sceso a 201 punti. Venerdì alta volatilità a causa delle “quattro streghe”, le scadenze di future e opzioni su azioni e indici. […] Bilancio negativo per le Borse europee nella settimana in cui le banche centrali di Stati Uniti, Svizzera e Inghilterra hanno rivisto al rialzo i tassi di interesse per contrastare la corsa dell’inflazione.
The European Insurance and Occupational Pensions Authority (EIOPA) has published its Annual Report 2021, setting out its activities and achievements of the past year.
The year 2021 continued under the influence of COVID-19 pandemic. EIOPA carried out a demanding Annual Work Programme and welcomed Petra Hielkema in September 2021 as Chairperson for a five year mandate.
https://www.eiopa.europa.eu/media/news/publication-of-annual-report-2021_en
The European Securities and Markets Authority (ESMA), the EU’s securities markets regulator, has published its Annual Report reviewing its achievements in 2021 in fulfilling its mission of enhancing investor protection and promoting stable and orderly financial markets in the European Union (EU), and focusing on its role in the supervision of EU-wide entities and its contribution on sustainable and digital finance.

L’iniziativa di Finriskalert.it “Il termometro dei mercati finanziari” vuole presentare un indicatore settimanale sul grado di turbolenza/tensione dei mercati finanziari, con particolare attenzione all’Italia.
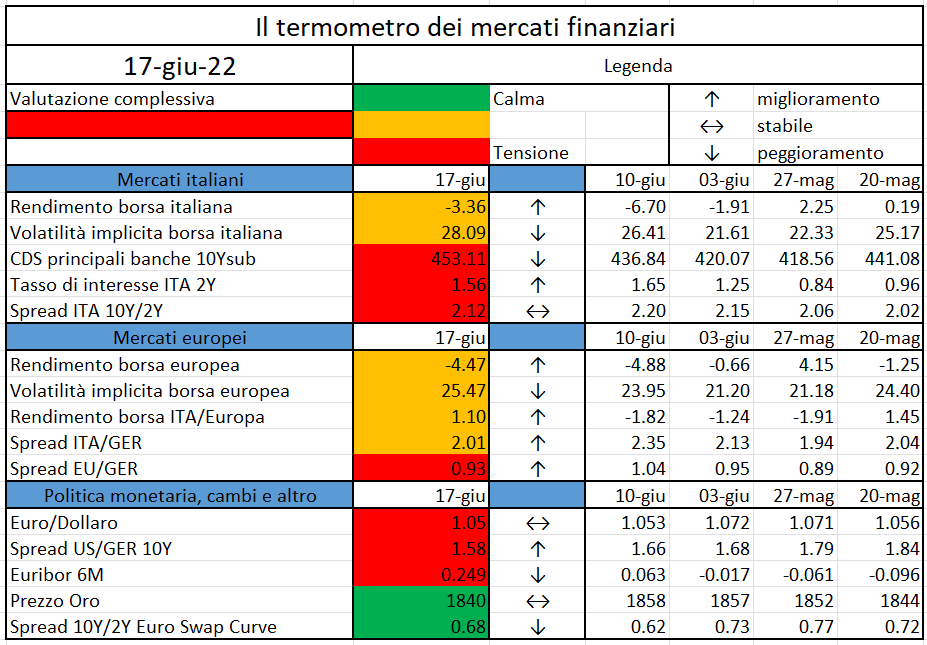
Significato degli indicatori
I colori sono assegnati in un’ottica VaR: se il valore riportato è superiore (inferiore) al quantile al 15%, il colore utilizzato è l’arancione. Se il valore riportato è superiore (inferiore) al quantile al 5% il colore utilizzato è il rosso. La banda (verso l’alto o verso il basso) viene selezionata, a seconda dell’indicatore, nella direzione dell’instabilità del mercato. I quantili vengono ricostruiti prendendo la serie storica di un anno di osservazioni: ad esempio, un valore in una casella rossa significa che appartiene al 5% dei valori meno positivi riscontrati nell’ultimo anno. Per le prime tre voci della sezione “Politica Monetaria”, le bande per definire il colore sono simmetriche (valori in positivo e in negativo). I dati riportati provengono dal database Thomson Reuters. Infine, la tendenza mostra la dinamica in atto e viene rappresentata dalle frecce: ↑,↓, ↔ indicano rispettivamente miglioramento, peggioramento, stabilità rispetto alla rilevazione precedente.
Disclaimer: Le informazioni contenute in questa pagina sono esclusivamente a scopo informativo e per uso personale. Le informazioni possono essere modificate da finriskalert.it in qualsiasi momento e senza preavviso. Finriskalert.it non può fornire alcuna garanzia in merito all’affidabilità, completezza, esattezza ed attualità dei dati riportati e, pertanto, non assume alcuna responsabilità per qualsiasi danno legato all’uso, proprio o improprio delle informazioni contenute in questa pagina. I contenuti presenti in questa pagina non devono in alcun modo essere intesi come consigli finanziari, economici, giuridici, fiscali o di altra natura e nessuna decisione d’investimento o qualsiasi altra decisione deve essere presa unicamente sulla base di questi dati.
L’iniziativa di Finriskalert.it “Il termometro dei mercati finanziari” vuole presentare un indicatore settimanale sul grado di turbolenza/tensione dei mercati finanziari, con particolare attenzione all’Italia.
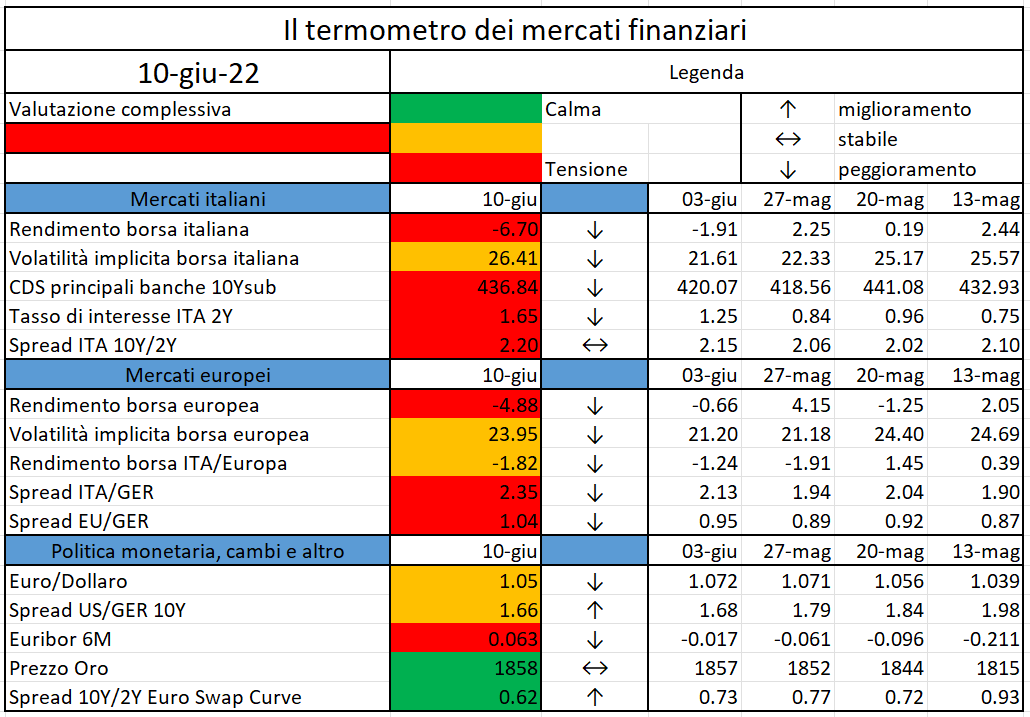
Significato degli indicatori
I colori sono assegnati in un’ottica VaR: se il valore riportato è superiore (inferiore) al quantile al 15%, il colore utilizzato è l’arancione. Se il valore riportato è superiore (inferiore) al quantile al 5% il colore utilizzato è il rosso. La banda (verso l’alto o verso il basso) viene selezionata, a seconda dell’indicatore, nella direzione dell’instabilità del mercato. I quantili vengono ricostruiti prendendo la serie storica di un anno di osservazioni: ad esempio, un valore in una casella rossa significa che appartiene al 5% dei valori meno positivi riscontrati nell’ultimo anno. Per le prime tre voci della sezione “Politica Monetaria”, le bande per definire il colore sono simmetriche (valori in positivo e in negativo). I dati riportati provengono dal database Thomson Reuters. Infine, la tendenza mostra la dinamica in atto e viene rappresentata dalle frecce: ↑,↓, ↔ indicano rispettivamente miglioramento, peggioramento, stabilità rispetto alla rilevazione precedente.
Disclaimer: Le informazioni contenute in questa pagina sono esclusivamente a scopo informativo e per uso personale. Le informazioni possono essere modificate da finriskalert.it in qualsiasi momento e senza preavviso. Finriskalert.it non può fornire alcuna garanzia in merito all’affidabilità, completezza, esattezza ed attualità dei dati riportati e, pertanto, non assume alcuna responsabilità per qualsiasi danno legato all’uso, proprio o improprio delle informazioni contenute in questa pagina. I contenuti presenti in questa pagina non devono in alcun modo essere intesi come consigli finanziari, economici, giuridici, fiscali o di altra natura e nessuna decisione d’investimento o qualsiasi altra decisione deve essere presa unicamente sulla base di questi dati
